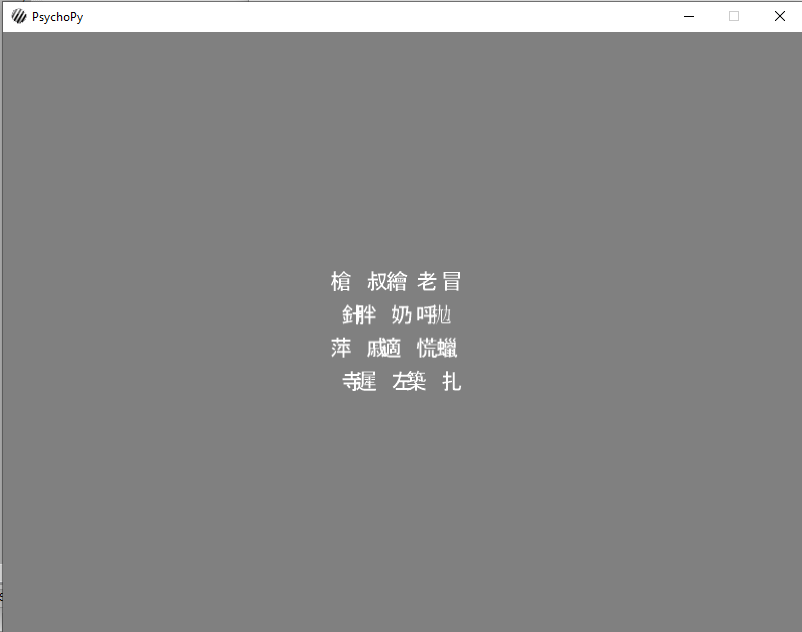
I need to present 20 chinese characters in a precise grid. This works pretty well with texstim if characters come from the english alphabet, but I can’t make anything work for chinese characters. Please see below for my code:
from psychopy import visual, core
import pandas, random, numpy, itertools
characterList = pandas.read_csv('letters.csv', header = None)
characterList = characterList.values.flatten()
win = visual.Window( units = 'pix')
pixelsWidthRadius = 50
numHorizontalChoices = 5
numVerticalChoices = 4
xLocations = numpy.linspace(-pixelsWidthRadius,pixelsWidthRadius,numHorizontalChoices)
yLocations = numpy.linspace(-pixelsWidthRadius,pixelsWidthRadius, numVerticalChoices)
choiceLocations = list(itertools.product(xLocations, yLocations))
for i in range(10):
random.shuffle(characterList)
allStimuli = characterList[:20]
# Create list of 20 individual random characters
choiceList = [None]*len(allStimuli)
for index in range(len(allStimuli)):
choiceList[index] = visual.TextStim(win, text=characterList[index],
height = 20,
alignText = 'center',
anchorHoriz = 'center',
anchorVert = 'center',
pos = choiceLocations[index],
font = 'SimHei')
# display all 20 characters
for character in choiceList:
character.draw()
win.flip()
core.wait(1)
Screenshot:

But, the problem occurs when instead of the CSV with english characters, I use a CSV with Chinese characters. If I change nothing else in the code, the locations of the chinese characters are very imprecise. This is a screenshot when I run the exact same code above, except I load chineseWords.csv instead of letters.csv:
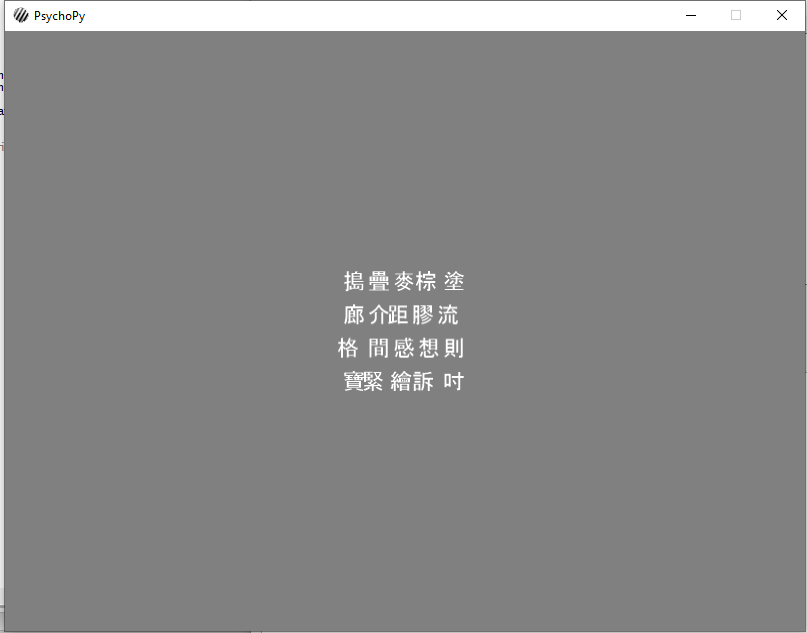
The spaces in between characters are more variable, and some even overlap.
Additional details:
-
I’ve tried changing the font, and it doesn’t appear to do anything with Chinese characters - I’ve tried inputting Arial, SimHei, Songti SC, Consolas.
-
When I open the chineseWords.csv file directly in notepad or wordpad, all of the characters line up beautifully in a column.
-
I’ve also tried replacing the textstim objects with textbox objects - and again it works for english text, but using my chineseWords.csv does not work at all, as the glyphs are simply invisible. The textbox code is:
choiceList[index] = visual.TextBox(win,
text=allStimuli[index],
font_size=21,
font_color= [-1,-1,-1],
textgrid_shape=[1, 1],
pos=choiceLocations[index],
grid_horz_justification='center',
units='pix',
grid_color=[1,-1,-1,0.5],
grid_stroke_width=1)
And when I try to input a font_name in the above code regardless of language, I get the following error
Traceback (most recent call last):
File "C:\Users\andre\Desktop\vision span\VisionSpanTextbox.py", line 39, in <module>
font_name = 'Arial')
File "C:\Program Files\PsychoPy3\lib\site-packages\psychopy\contrib\lazy_import.py", line 120, in __call__
return obj(*args, **kwargs)
File "C:\Program Files\PsychoPy3\lib\site-packages\psychopy\visual\textbox\__init__.py", line 384, in __init__
self._font_name, self._font_size, self._bold, self._italic, self._dpi)
File "C:\Program Files\PsychoPy3\lib\site-packages\psychopy\visual\textbox\fontmanager.py", line 212, in getGLFont
if len(font_infos) == 0:
TypeError: object of type 'NoneType' has no len()
Ultimately, I need the chinese characters in a precise grid - where each position can be precisely known and controlled. I’ve been working at this for a while, and though everything is straightforward in english, I haven’t found any solution for the chinese characters. Thank you!
chineseWords.csv (13.1 KB)
letters.csv (81 Bytes)