Apologies if this issue has been posted before. I have a conditions file called cond.xlsx with a single column and 6 rows, each containing a different item of fruit.

I would like to write a code component at the beginning of my experiment which randomly sorts the rows into three conditions, each containing 2 rows. Ideally this would create a ‘temporary’ dict object (apologies if I’m using incorrect terminology) that would allow me to call rows from each condition in subsequent loops in the experiment.
Here is my code:
conditions = data.importConditions(u’cond.xlsx’)
shuffle(conditions)
cond_A = conditions[0:2]
cond_B = conditions[3:4]
cond_C = conditions[5:6]
I would then call specific conditions in subsequent loops:

Ultimately I would like a way to record which items of fruit were assigned to each condition at the end of the experiment. However, when I try to run the experiment as-is, I get the following error

################
If anyone can suggest a fix (and/or a way to save a record of which rows/items of fruit were assigned to each condition) I would be very grateful for the advice. Thanks in advance!
The selected rows field has to contain integers (ie the indices of the rows, not the content of the rows themselves).
You can achieve what you want without any code.
- Put some fixed ranges in each of your loops (eg
[0, 1] followed by [2, 3], etc).
- Set each loop to be random but supply a common seed value so that the randomisation is constant across each loop.
- I guess you want the randomisation to vary across subjects however, so enter a new seed value on each session into the information dialog at the start of the experiment, and refer to that variable from the
expInfo dialog in each seed field.
Hi Michael
Thanks for the reply! I’m having trouble calling the expInfo as you suggested. I entered a new row in ‘Experiment settings’:
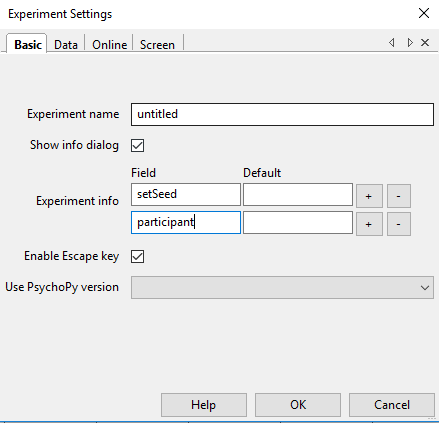
and then entered expInfo.setSeed in the seed field for each loop. This causes the following error:
AttributeError: 'dict' object has no attribute 'setSeed'
I also tried automating the process by instead creating a code component with
setSeed = random.randint(0,1000) # should select a random seed value between 0 and 1000
This runs fine (and seems to be selecting random rows, as intended), but after running the experiment a few times I realized it’s pulling the SAME selection of rows each time, so random.randint must be assigning the same value to setSeed each time…?
The dot notation gives you access to the methods of the dictionary class, things like .keys(), copy(), etc. You look up individual values in Python dictionaries like this:
expInfo['setSeed']
See Python - Dictionary
Ah! That makes sense. I tried using expInfo[‘setSeed’] and got the following error:
File “mtrand.pyx”, line 684, in mtrand.RandomState.seed (numpy\random\mtrand\mtrand.c:13996)
TypeError: Cannot cast array from dtype(‘<U2’) to dtype(‘int64’) according to the rule ‘safe’
My understanding is that the value from expInfo[‘setSeed’] should be converted to float, which I tried to do with a code component:
randValue = expInfo[‘setSeed’]
randSeed = map(float, randValue)
But no luck! Can you suggest a work around? Again, thanks in advance for the help 
Hi Michael,
Thanks for the reply! The suggestion worked (in that no errors occurred), however I found that this pulled exactly the same rows for each condition on every run, regardless of what seed value I provided 
SO I figured out a workaround. I did away with the seed values, and created a shuffled list of values corresponding to rows in my conditions file:
import random
row_vals = [0,1,2,3,4,5]
shuffle(row_vals)
I then assigned a range of indices in the (now shuffled) list to keys in a dictionary:
a = row_vals[0:2]
b = row_vals[4:6]
dict = {'cond_A':a,'cond_B':b}
and called a random key for each loop (note that in the builder I set the rows field of my two loops to $loop1 and $loop2)
x = random.choice(dict.keys())
loop1 = []
loop2 = []
loop1 = dict.get(x)
if loop1 == dict.get('cond_A'):
loop2 = dict.get('cond_B')
elif loop1 == dict.get('cond_B'):
loop2 = dict.get('cond_A')
note that this can be tweaked to include a third condition (in this case, cond_C) using nested if-else function:
if loop1 == dict.get('cond_A'):
if random.random()>0.5:
loop2 = dict.get('cond_B')
else:
loop2 = dict.get('cond_C')
elif loop1 == dict.get('cond_B'):
if random.random()>0.5:
loop2 = dict.get('cond_A')
else:
loop2 = dict.get('cond_C')
elif loop1 == dict.get('cond_C'):
if random.random()>0.5:
loop2 = dict.get('cond_A')
else:
loop2 = dict.get('cond_B')
1 Like