Dear all,
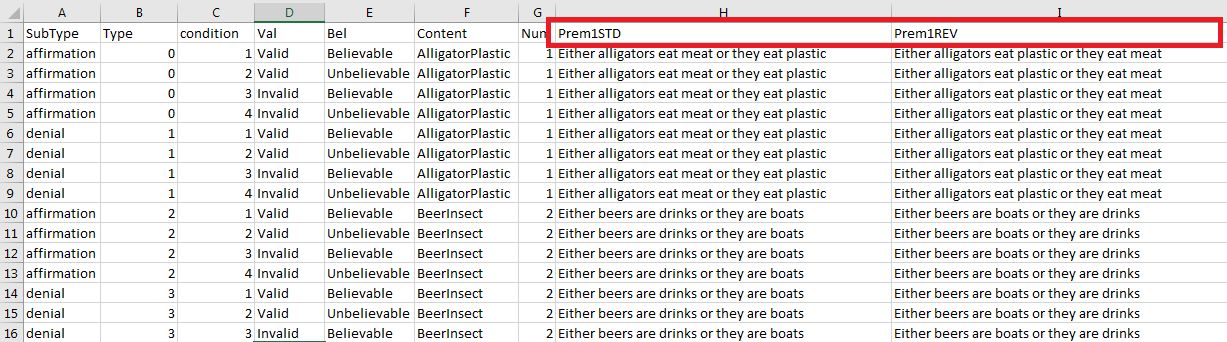
I intend to show participants 3 statements and ask them to rate how much they like the last statement. The problems are disjunctions with 3 premises. For example:
Premise 1: Either the sky is blue or it is white.
Premise 2: The sky is not white.
Conclusion: The sky is blue.
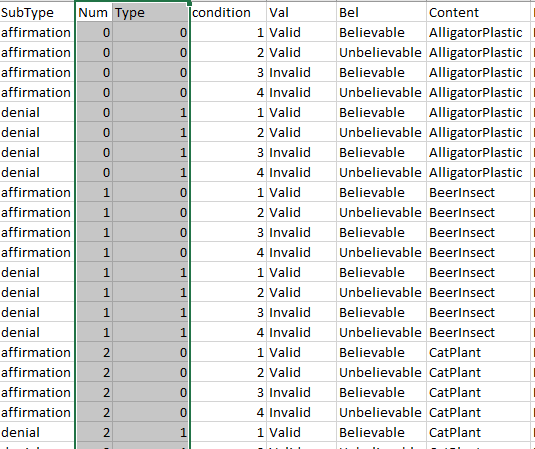
This is what I created in Builder view:

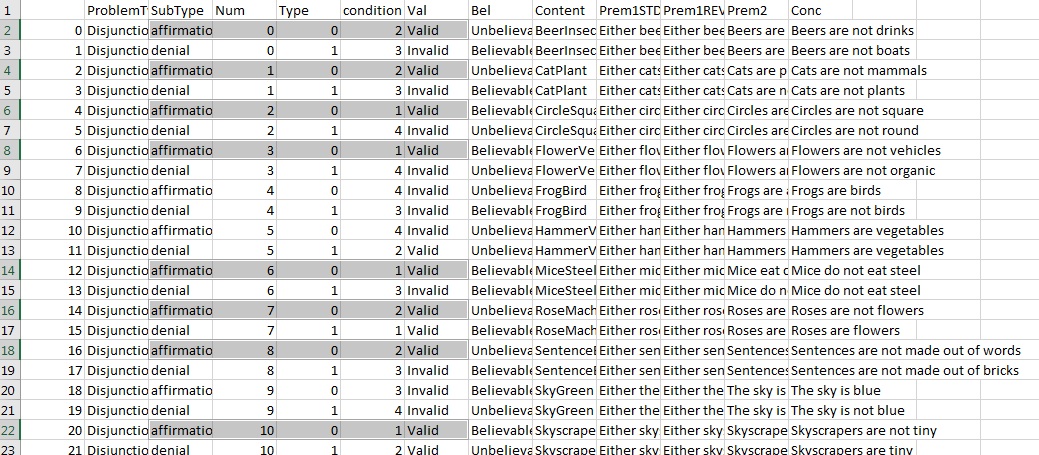
This kind of problem can be logically valid or invalid and can be believable and unbelievable, so making 4 different kind: valid believable, invalid believable, valid unbelievable, invalid unbelievable. So I created 4 different states for each of my affirmative or denial disjunction (look the condition file).
What I now want is to randomly select one of each states as in the following picture:
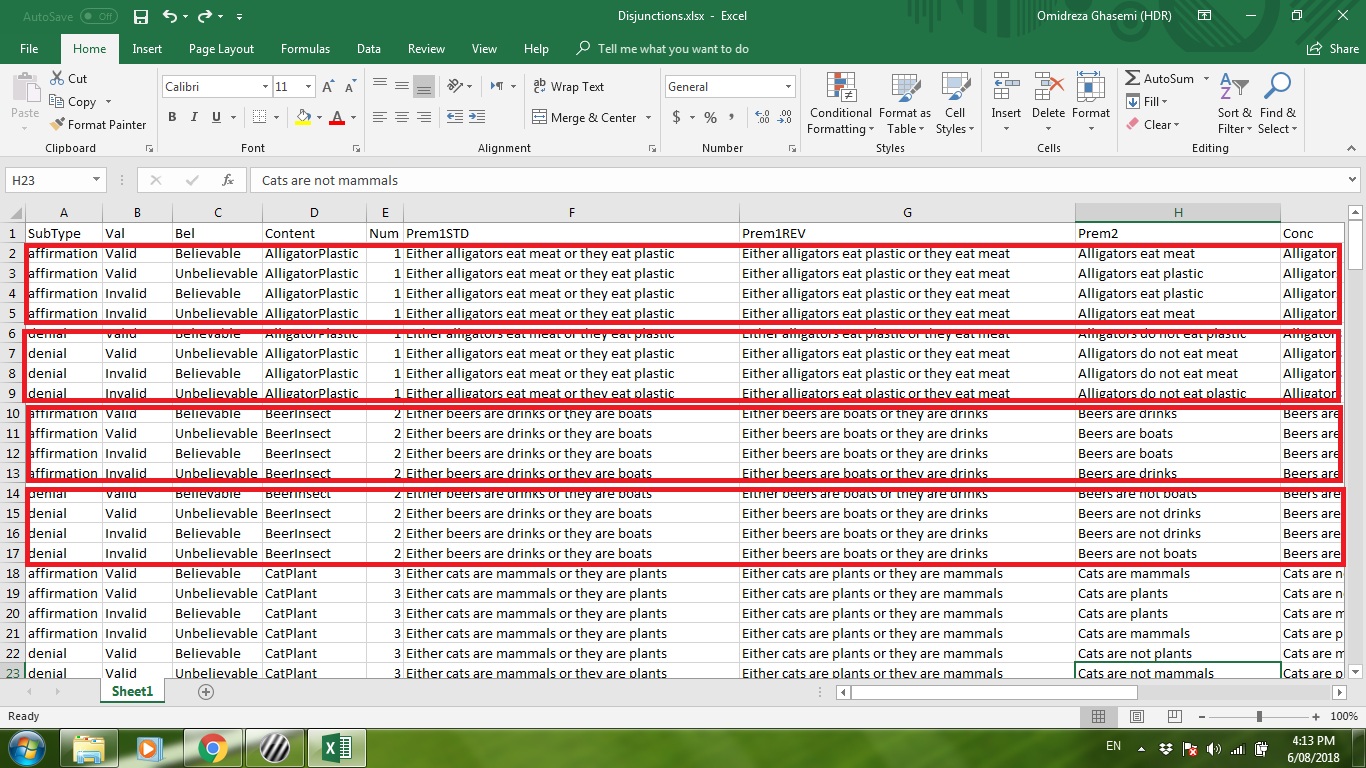
I want to randomly present one row from every four rows of my conditional file. However, there is one limitation: At the end of the trials, there must be same number of each valid believable, invalid believable, valid unbelievable, invalid unbelievable.
I would appreciate any comment.
Disjunctions.xlsx (16.8 KB)